(Pascal programmers, please interpret function as "function or procedure". Fortran programmers, as "function or subroutine.")
We saw in note6a how a program can call a function using jal, and the function returns using jr $ra. This is obviously not the whole story, because we are still not able to have a function call another function, because that would wipe out the return address in $ra. There is need for a standard method or saving multiple return addresses (and other registers as well). The elegant solution is known as "The Stack."
As a non-trivial example, the fields you fill out in forms posted over the internet have to be "URL encoded" to avoid confusion about the structure of the data. (space & % = " for example have special meaning, so these characters need to be represented some other way.) The chosen solution is to encode letters and numbers as themselves, spaces as plus signs (+), and everything else as 3 characters of the form %hh, where hh is the special character's hexadecimal value. For instance, '=' would be represented by %3D, and '+' by %2B. (2B or not 2B: of course this only applies to a real '+' in the data, not one that is representing a space!)
Anyway, this is complex enough that it will pay to structure the problem of producing a URL-encoded string by calling some sub-functions. The ones that come to mind are:
With these defined, the problem can be expressed in pseudo code as a function with 2 arguments, pointers to the plain string, and (space for) the encoded string. A refinement would be to check for enough space.
URLencode (plain, encoded)
FOR each character ch in plain, store in encoded,
CASE ch OF
space: '+'
AlphaNumeric: ch
(other): '%'
bin2hex (left nibble of ch)
bin2hex (right nibble of ch)
END FOR
You can see that other functions will need to be called, and that we will need two pointers to step through the two strings, as the encoded string will be larger than the original if it contains any special characters. The next step is to refine this algorithm further. C is the language probably closest to assembler, so I refined it to working C code, before proceeding with assembler.
To start with, let's get the little functions on the table. Here is
# char bin2hex (binary) converts 4 bits (least significant) of input to an
# ASCII character giving the hex value. '0'-'9' or 'A'-'F'
# registers:
# $a0, input argument, unchanged
# $v0, char value returned
# no other registers used
bin2hex:
andi $v0, $a0, 0x0f # mask off 4 lower bits
ori $v0, $v0, 0x30 # make it ASCII digit
ble $v0, '9', numeric #if hex value A..F, then
add $v0, 7 # add 7, since there are 7 characters
numeric: # between '9' and 'A'
jr $ra # RETURN
Evaulates boolean expression (ch >= 'A' and ch <= 'Z') or (ch >= 'a' and ch <= 'z') # or (ch >= '0' and ch <= '9')
This could be done "on the fly" by careful arrangement of 6 branch instructions. There is a more reliable way, now that we know about the logical instructions. It involves a new bunch of instructions, the "set" instructions, which are similar to "branch" in that they compare two operands, but instead of branching, they store the boolean result in the desination register. We then use boolean instructions with these values. Here is how the code starts, ch in $a0:
sge $t5,$a0,'A'
sle $t6,$a0,'Z'
and $t7,$t5,$t6 #(ch >= 'A' and ch <= 'Z')
This being RISC, it turns out that some very ugly machine code is generated by SPIM, because the only machine instructions available are slt, beq and bne. Normally the best policy is to let the assembler or compiler do its work, even if the resulting code may be less than optimal. Compilers are getting very good at optmizing their code. In this case, since you may be looking at this code in SPIM, I have optmized slightly by getting rid of the equal part of the comparisons, because we can test for strict inequality by adding or subtracting 1 to the constant. (Due to a bug in the simulator, it handles '9'+1 fine, but muddles up 'A'-1). Anyway, here is the whole thing:
#############################################################
# boolean function AlphaNumeric (ch)
# $a0: argument ch, unchanged
# $v0: boolean value output, TRUE (1) if ch is letter or number
# Uses registers t5, t6, t7, t8
#############################################################
AlphaNumeric:
sgt $t5,$a0,0x40 #ch > 'A'-1
slt $t6,$a0,'Z'+1 #ch < 'Z'+1
and $t7,$t5,$t6 #(ch >= 'A' and ch <= 'Z')
sgt $t5,$a0,0x60 # ch < 'a'-1
slt $t6,$a0,'z'+1
and $t8,$t5,$t6 #(ch >= 'a' and ch <= 'z')
or $t8, $t8,$t7 # $t8 = big or small letter
sgt $t5,$a0,0x2f # ch > '0'-1
slt $t6,$a0,'9'+1
and $t7,$t5,$t6 #(ch >= '0' and ch <= '9')
or $v0, $t8,$t7 # $v0 = AlphaNumeric truth value returned
jr $ra
As soon as several program units (main and functions) are in use, it gets more difficult for humam programmers to keep track of registers in use. For one thing, it may be hard to remember just where to put arguments to a function, for another, a function we call may "trash" a register we were using. The following conventions are recommended:
Each of the functions given above follows these conventions. Both expect an argument in $a0, and return a result in $v0. This makes it easier for us to remember how to use them. In addition their use of the $t registers is documented. This makes it easier for designing URLencode. Since it is both called and a caller, it would need to use the $s registers for values saved past calls, but would need to save and restore those it used, because there is no telling which $s registers might be in use. Fortunately, we can see that only $a0, $v0, and $t5-$t8 are used by the functions we will call.
Therefore, we only need to save $ra (we want to return to our caller, obviously!) and $a0 (to be nice to our caller, who may expect the pointer to the plain string to still be there.) Now, lets consider where we can store these things:
1. We could declare variables in the data segment for each register to be saved by each function. This gets messy. And it doesnt work if a function calls itself.
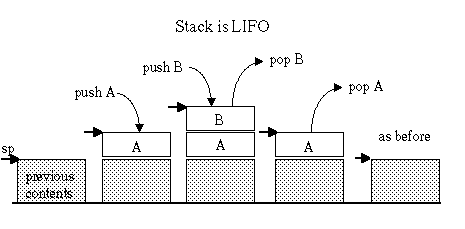
2. Use a stack Like a stack of papers, a stack is known to accountants as a "Last In, First Out" (LIFO) data structure. This is ideal for functions as typically they need to save some registers on the way in, and retrieve the values on the way out. As functions call each other, they pile up more items on the stack, as each one returns, they (must!) remove the values they piled on. This is such a useful method that all operating systems set up space for a stack for programs, and initialize a stack pointer.
By custom, computer stacks grow "downward" from higher to lower memory addresses. The stack pointer always points to the top word on the stack. The permitted stack operations are:
These customary terms alude to a stack of plates on a cafeteria counter, the kind that uses a spring pushed down by the weight of the plates. When plates are removed, the stack "pops" up. Ideally, it is impossible to take any but the top plate off the stack.
This figure shows the operations on a stack. In any 32-bit machine, a 32 bit word is always pushed or popped, so the sp is always kept a multiple of 4.
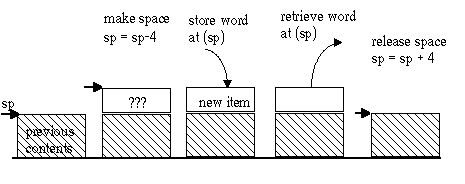
CISC processors typically have instructions that implicitly manipulate the stack pointer, usually named SP. They are PUSH, POP, CALL and RET. The last two store and retrieve return addresses directly to and from the stack.
In MIPS, the stack pointer is $29, named $sp. It is only made special by the fact that the operating system sets up the stack for you, with $sp pointing to the initial top of stack. To push, the sequence is
sub $sp, 4 #PUSH on the stack sw $ra, ($sp) #our return address
Pop reverses this order, first retrieving the value previously pushed, then incrementing the stack pointer:
lw $ra, ($sp) #POP our return address from the stack add $sp, 4 #top of stack back as it was before the PUSH
The stack is a last-in-first-out data structure. This means you need to pop items in the reverse order they were pushed. It is generally important to pop precisely the items that were pushed, rather than abandoning them.
URLencode:
# function URLencode (plain, encoded, maxlength)
######## entry code: save registers
sub $sp, 4 # PUSH return address
sw $ra, ($sp)
sub $sp, 4 # PUSH a0
sw $a0, ($sp) # (be nice, restore caller's register)
########################
While the exit code looks like this. Note that the order of POPs is reversed from the order of PUSHes. Once the stack is used, it is extermely important to exit in this way. The stack must have exactly the same contents upon return from a function that it had upon entry. Other functions depend on this!
############ exit code: restore registers, POP in reverse order to PUSH
endURL:
lw $a0, ($sp) # POP start of string addr
add $sp, 4
lw $ra,($sp) # POP return address
add $sp, 4
jr $ra ##### return, using newly restored $ra
Finally, we are in a position to write the whole code for URLencode. Have a look. Sandwiched between the entry and exit code above, is simply a loop to go through the input string. In addition to the pointer moving through that string, we need another pointer to move through the output string. I have used $t0 and $t1 for these, and $t2 for the individual characters. Inside the loop is a 3 way IF. One of the conditions calls AlphaNumeric to get its truth value, another (for special characters) makes 2 calls to bin2hex.
The whole thing, including a main program to test it out, has a few extra refinements, added after the basic algorithm was implemented. A third argument, $a2, specifies the maximum space available for the output string. This is good safe programming practice, as otherwise other variables could be overwritten, with usually bad results. At the beginning of each successive loop iteration, we make sure there is space for 4 characters, %hh, and a null byte.
See also Code from a real compiler for stack animation of figure on p. 103 of Waldron.